End-to-End Machine Learning Example- California Housing Prices
Est. read time: 3 minutes | Last updated: July 27, 2026 by John Gentile
Contents
![]()
Here we’ll use housing price dataset from the 1990 CA census from StatLib repository which contains metric such as population, income, and housing price for each block group (the smallest geographical unit for which the census publishes sample data, typically 600 to 3,000 people). Our goal is for our ML model to accurately predict the median housing price in any district, given all other metrics.
Model Approach
Since we are given labeled training examples (accurate census sample data which gives the expected output- median housing price- for each set of features), we can conclude that this is definitely a supervised learning task. Since we are looking to predict a value, it is a regression task, but more specifically, a multiple regression proble, since we need to consider multiple features to make the output prediction (e.g. features like population, median income, etc.). It is also considered a univariate regression problem since we only need to predict a single value for each district; conversely if we needed to predict multiple values, it would be a multivariate regression problem. Finally, since data is not continuously streaming into the system and the dataset is small enough to fit in memory, batch learning is fine for this model.
Performance Measure
Typical for regression problems, we will use the Root Mean Square Error (RMSE) measurement to give an idea of how much error the system is making with predictions at any given time. RMSE is calculated by:
Where:
- is the number of samples in the dataset being currently measured
- is a vector of all feature values (excluding label, ) of the i-th instance in the dataset
- For instance, if a district in the dataset has a longitude location of -118.29deg, latitude of 33.91deg, population of 1416, and a median income of $38,372 - with the label/median house value of $156,400- then the vector and label would look like:
- is the matrix containing all feature values (excluding labels) for all instances in the dataset, which with the above example values, looks like:
- is the system’s prediction function (aka hypothesis); it’s the system’s output given a feature vector ,
Once could use another performance function which measures deltas between the prediction vectors and target value vectors, called Mean Absolute Error (MAE):
These various distance measures are also called norms:
- Computing RMSE corresponds to the Euclidean norm, or the norm, denoted colloquially as (or more specifically)
- Computing MAE correspongs to the Manhattan norm (because it can measure the distance between two city points where you can only travel in orthogonal blocks), or the norm, denoted
In general, the norm of a vector containing elements is defined as:
The higher the norm index, the more it focuses on large values and neglects small ones, hence why RMSE is more sensitive to outliers than MAE, however when outliers are exponentially rare, RMSE performs very well and is preferred.
Dataset Creation
Dataset Download
Here we will download the comma-separated values (CSV) file that contains our housing dataset, and load it into memory using pandas.
import os
import tarfile
import urllib
import pandas as pd
DL_FOLDER = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DL_FOLDER + "datasets/housing/housing.tgz"
# create function to easily download & extract housing dataset tarball
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
os.makedirs(housing_path, exist_ok=True)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
fetch_housing_data() # download now
housing = load_housing_data()
housing.describe() # show a summary of the numerical attributes
# render plots within notebook itself
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()
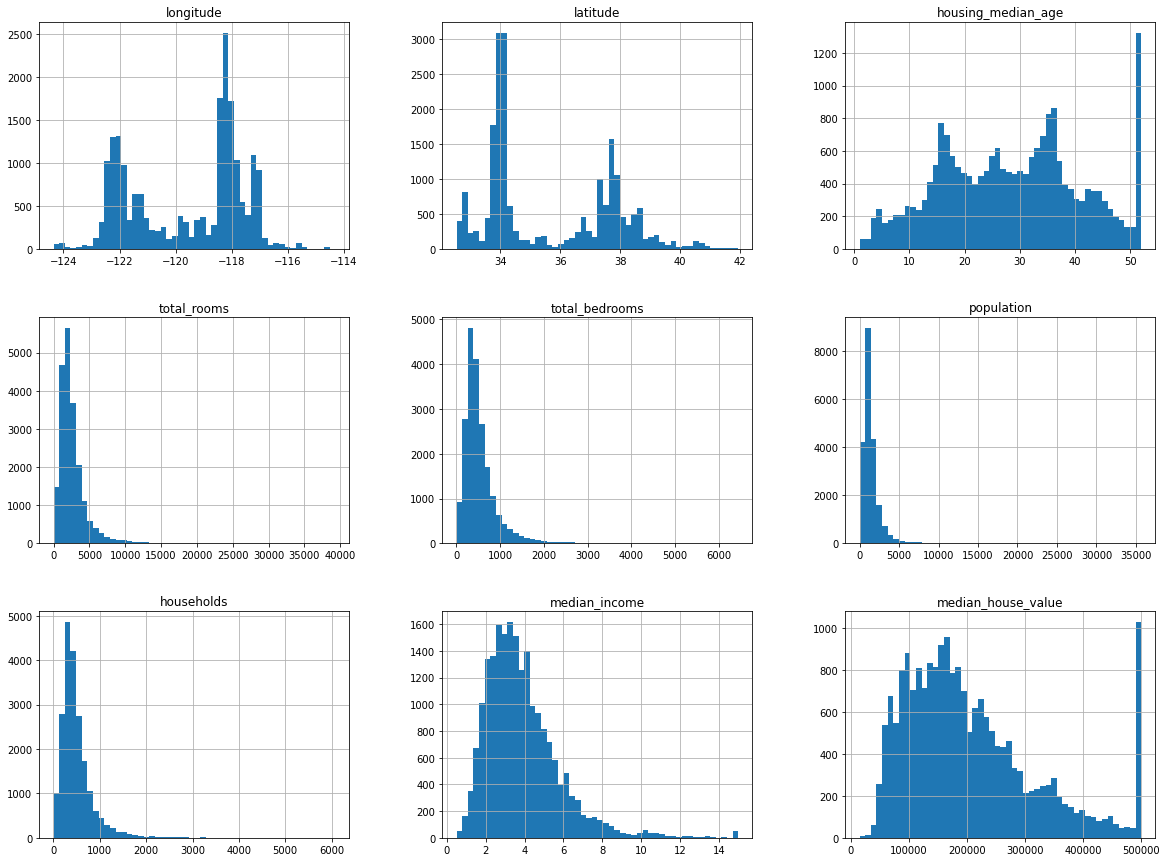
Note that in the above histogram plots, there are a couple important points:
median_incomevalues were normalized to values between 0.5 and 15 (e.g. a value of 3 is equivalent to about $30k). This preprocessing is fine, and common in ML tasks.housing_median_ageandmedian_house_valuevalues are capped, which may cause an issue since the house value is our target attribute (label), and you don’t want the ML model to learn that prices never go above that limit.- Attributes have very different scales, which we’ll need to tackle with feature scaling.
- Many of the plots are tail-heavy (the distribution of values is not symmetrical about the mean) which can be difficult for some ML algorithms to detect patterns.
Creating Test Set
Creating a test set could be as simple as picking some random subset of the dataset (usually around 20%, or less with larger datasets) and set them aside:
import numpy as np
def split_train_test(data, test_ratio):
shuffled_idx = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_idx = shuffled_idx[:test_set_size]
train_idx = shuffled_idx[test_set_size:]
return data.iloc[train_idx], data.iloc[test_idx]
train_set, test_set = split_train_test(housing, 0.2)
print("Training dataset size: %d" % len(train_set))
print("Testing dataset size: %d" % len(test_set))
Training dataset size: 16512 Testing dataset size: 4128
While the above works, each time you run the code, a different test data set is generated; over time this means your model will see the whole dataset, which you want to avoid. One way to prevent this would be to set the random number generator’s seed (e.x. np.random.seed()) before calling np.random.permutation().
Maintained by John Gentile • Found a problem on this site? File an Issue
This work is licensed under a Creative Commons Attribution 4.0 International License.![]()