Linear Algebra
Est. read time: 3 minutes | Last updated: May 28, 2025 by John Gentile
Contents
![]()
from sympy import *
init_printing()
Overview
Notation and Types
-
Scalars: a single value/number, usually denoted with lowercase variable letters, also specified with what type of number; for instance, a real-valued scalar can be shown as:
- Vectors: a one-dimensional array of numbers, typically shown in bold lowercase variables like:
- To say each element of the above vector is real, with elements, the vector lies in the set formed by times the Cartesian product or
- To index a set of elements of the vector- for instance elements - we can define a set and denote the subset of for those elements as . As an inverse, to exclude a set of indices of a vector with a given set, one can denote which is the vector containing all elements except .
- Matrices: a 2-D array of numbers, denoted by a variable with bold & capitalized typeface such as:
where the subscript numbers of each element identify the 2-D position within the matrix.
- A real-valued matrix with a height of and width can be shown as
- A “” symbol can be used to identify a cross section of a matrix in one dimension; for instance, to index all elements in the first row of the matrix , we can use the notation
- gives element of the matrix computed by applying the function to
- Tensors: in arrays with more than two dimensions/axes, tensors can be used with the typeface
- The element at coordinates of the tensor is
Vector and Matrix Operations
- Transpose: for a matrix, the transpose is the mirror image of the matrix across the main diagonal line, running from the top left corner to the bottom right. The transpose operation of a matrix is shown as
- Since vectors are essentially 1-D matrices with one column, the transpose of a vector is a matrix with only one row. Similarly, we can write a vector as a row vector, and then turn it into a column vector with a transpose, as
M = Matrix([[1,2,3], [4,5,6]])
M
M.T
- Scalar Addition/Multiplication: scalars can be simply added, subtracted, multiplied or divided into a matrix by performing the operation with the scalar on each element of the matrix. For instance, to multiply a matrix by scalar and add by scalar :
- Matrix Addition: matrices can be added together if they have the same dimensions/shape by simply adding their corresponding elements:
-
Vector Broadcasting: a simplification found in some deep learning writings shows the simple addition of a matrix and a vector, yielding another matrix, for instance . This denotes the vector is added to each row of the matrix , which is shorthand for an implicit step of defining another intermediate matrix with vector copied in each row before performing the addition.
-
Dot Product:
-
Vector & Matrix Multiplication:
- In matrix multiplication, the order of operations matter, as well as the matrix sizes; given two matrices, and , the matrix multiplication results in output matrix . This shows two important properties of matrix multiplication:
- The inner dimensions of both matrices (number of columns in first matrix operand, and number of rows in second matrix operand) must be equal.
- The output matrix size matches the dimensions of the outer sizes of both matrix arguments (the number of rows in first matrix operand by the number of columns in the second matrix operand).
- As another example, when multiplying a 1x3 row vector with a 3x1 column vector, a scalar (1x1) is the result, but when the operands are reversed, a 3x3 matrix is the result:
- In matrix multiplication, the order of operations matter, as well as the matrix sizes; given two matrices, and , the matrix multiplication results in output matrix . This shows two important properties of matrix multiplication:
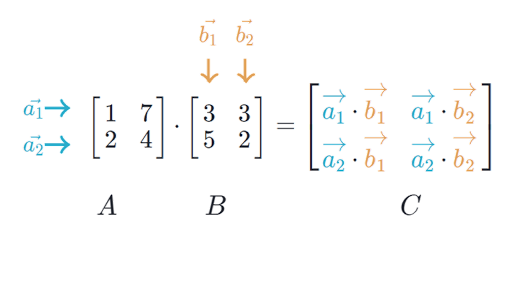
References
- 3Blue1Brown
- Linear Algebra Done Right
- Linear Algebra Done Wrong - Sergei Treil
- kenjihiranabe/The-Art-of-Linear-Algebra: Graphic notes on Gilbert Strang’s “Linear Algebra for Everyone”
- Deep Learning Book- Linear Algebra
- The Matrix Cookbook
- Toeoplitz matrix for correlation
- Algebra, Topology, Differential Calculus, and Optimization Theory For Computer Science and Machine Learning
- Making sense of principal component analysis, eigenvectors & eigenvalues
- Matrix Methods in Data Analysis, Signal Processing, and Machine Learning- MIT OpenCourseWare
- The matrix calculus you need for deep learning
- Introduction to Linear Algebra for Applied Machine Learning with Python
Maintained by John Gentile • Found a problem on this site? File an Issue
This work is licensed under a Creative Commons Attribution 4.0 International License.![]()